Your AI Partner
In the realm of Embedded Computing, optimized SW can be the differentiator between success or inability to realize your application.
Our experience with NVIDIA has led us to develop a unique set of services (SW/HW).
Our goal is to make your idea realize with the shortest Time to Market.
Our team of experts excels at optimizing system performance, from HW architecture, video channels and data acquisition to inference, using NVIDIA SDKs, platforms, debug tools, custom images, and Board Support Packages (BSP).
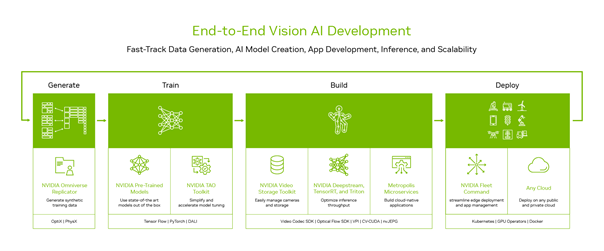
Our Approach
Profiling Your Needs
Our initial step involves a collaborative session with your team to profile your current accurate deployment scenario, objectives, and specific requirements.
We will propose a comprehensive solution package designed to meet your goals. This package will include all necessary components, meticulously specified to align with your NVIDIA hardware and platform requirements.
Optimized System Configuration
Our team will expertly create custom system images with BSP for seamless integration with NVIDIA’s platforms. We’ll configure NVIDIA’s SDKs to match your hardware and ensure efficient operation from data acquisition to inference, optimizing your system for peak performance with NVIDIA technology.
From Algorithm to Product
We specialize in transforming your AI algorithms into robust, market-ready products. Our team will integrate these algorithms into the pipeline, ensuring they are fine tuned to capitalize on NVIDIA’s advanced hardware and platforms. This process is designed to implement and elevate your algorithms, turning innovative ideas into high-performing, proud products that stand out in the industry.
Continuous Support and Optimization
Our ongoing support ensures your system’s continuous improvement with OTA updates, Remote Monitoring and Management (RMM), and constant improvement of your models. Our team is here to assist whenever you face challenges or need enhancements, including new NVIDIA features. We provide expert guidance to optimize NVIDIA platforms, ensuring high performance and value for your products.
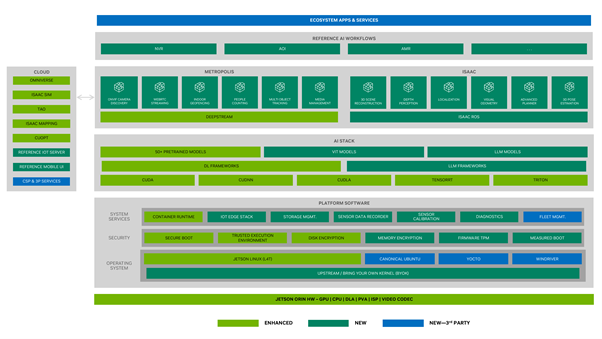
Metropolis Solutions
CRG is NVIDIA’s Metropolis on Jetson partner. We enable the use of NVIDIA’s powerful Metropolis APIs and Microservices platform for developers to easily develop and deploy applications on the NVIDIA Jetson edge-AI platform.
Metropolis features GPU-accelerated SDKs and developer tools that give you a faster, more cost-effective way to build, deploy, and scale AI-enabled video analytics and IoT applications—from the edge to the cloud.
Generative AI Solutions
Unlike other embedded platforms, Jetson is capable of running large language models (LLMs), vision transformers, and stable diffusion locally.
Generative AI dramatically improves ease of use by understanding human language prompts to make model changes. Those AI models are more flexible in detecting, segmenting, tracking, searching and even reprogramming — and help outperform traditional convolutional neural network-based models.

- Accelerated APIs and quantization methods for deploying LLMs and VLMs on NVIDIA Jetson
- Optimizing vision transformers with NVIDIA TensorRT
- Multimodal agents and vector databases
NVIDIA Tools and SDKs
Data Generation
Omniverse Replicator
NVIDIA Omniverse Replicator is a robust framework for generating synthetic data specifically designed to accelerate the development of AI models. It’s a vital component of the NVIDIA Omniverse platform, a collaborative and scalable virtual environment. Replicator focuses on producing high-quality, realistic synthetic datasets that can be used to train AI models more efficiently, especially in scenarios where real-world data is scarce or difficult to obtain. This tool is precious in fields like robotics, autonomous vehicles, and computer vision, where accurate and diverse data is crucial for training robust AI systems.
Training
TAO
NVIDIA TAO is a streamlined framework for efficiently customizing and optimizing AI models. It provides pre-trained models across various domains, enabling users to fine-tune them with their data. Optimized for NVIDIA GPUs, TAO accelerates the training process, making AI deployment quicker and more cost-effective. It’s ideal for enterprises and developers leveraging AI with minimal resource investment, offering scalability from edge devices to the cloud.
Inferencing
Nsight
NVIDIA Nsight SDK is an advanced suite of tools designed for performance profiling and debugging of GPU-accelerated applications. It offers in-depth insights into compute operations, helping developers optimize the performance of their applications on NVIDIA GPUs. Nsight facilitates detailed analysis of compute kernels, memory usage, and workload distribution, making it an essential tool for maximizing efficiency and speed in GPU computing tasks. Ideal for developers working in high-performance computing, gaming, and AI, Nsight SDK ensures applications fully leverage the power of NVIDIA’s GPU technology.
TensorRT
TensorRT is NVIDIA’s high-performance deep learning inference optimizer and runtime engine. It is designed to deliver low latency and high throughput for deep learning inference applications. TensorRT optimizes trained deep learning models to improve inference performance on NVIDIA GPUs, making it ideal for deploying AI applications in environments where resources are constrained, and efficiency is critical. With its support for multiple data types and optimized libraries, TensorRT is a vital tool for developers looking to streamline deep learning models for production environments, particularly in fields like autonomous vehicles, robotics, and healthcare.
Triton Inference Server
NVIDIA Triton Inference Server is an open-source platform for deploying AI models across various frameworks like TensorFlow and PyTorch at scale. Optimized for CPU and GPU environments, Triton offers features like dynamic batching for high throughput, model versioning, and robust monitoring, ensuring efficient and scalable AI deployments.
GStreamer
Experience the power of multimedia innovation with GStreamer, brought to you by our expert software engineering team. GStreamer isn’t just a tool; it’s a versatile, open-source framework enabling us to manage and stream a wide range of media efficiently. Our mastery of its modular architecture and extensive plugin library allows us to deliver custom, high-quality multimedia solutions for various needs and industries. Trust us to transform your multimedia challenges into successful, cutting-edge solutions.
DeepStream
NVIDIA DeepStream SDK is a robust framework for building AI-powered video analytics applications. Optimized for NVIDIA GPUs, it enables real-time processing and analysis of multiple video streams. DeepStream is highly scalable and integrates seamlessly with major AI frameworks like TensorFlow and PyTorch. It’s ideal for surveillance, traffic management, and retail analytics applications, providing an efficient solution for deploying AI models on various platforms, from edge devices to cloud environments.

Isaac
From smart automation in manufacturing to last-mile delivery, robots are becoming more ubiquitous in everyday life. However, industrial, and commercial robotics development can be complex, time consuming, immensely challenging, and expensive. Unstructured environments across many use cases and scenarios are also common. The NVIDIA Isaac™ robotics platform addresses these challenges with an end-to-end solution to help decrease costs, simplify development, and accelerate time to market.
Clara
NVIDIA Clara™ is a platform of AI applications and accelerated frameworks for healthcare developers, researchers, and medical device makers creating AI solutions to improve healthcare delivery and accelerate drug discovery. Clara’s domain-specific tools, AI pre-trained models, and accelerated applications are enabling AI breakthroughs in numerous fields, including medical devices, imaging, drug discovery, and genomics.
Riva
NVIDIA Riva is a state-of-the-art software suite designed to create optimized AI-powered speech applications. It offers a range of tools and capabilities to develop and deploy highly accurate speech recognition, natural language understanding, and text-to-speech services. Optimized for NVIDIA GPUs, Riva enables real-time performance and scalability, making it ideal for applications in interactive voice response systems, virtual assistants, and conversational AI agents. With Riva, businesses and developers can easily integrate advanced speech capabilities into their products, enhancing user experience and interaction.
NeMo
NVIDIA NeMo™ is an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere. It includes training and inferencing frameworks, guard railing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost-effective, and fast way to adopt generative AI.

